Blog
Optymalizacja promptów to nowa optymalizacja kodu
Praca z modelami, np. w celu budowania oprogramowania, to zupełnie co innego niż budowanie narzędzi, które modeli używają jako elementu procesu.
Tutaj pojęcie wewnętrznych testów i ciągłej optymalizacji nabiera zupełnie nowego znaczenia.
Logi to fundament
Szczegółowe logi każdej wykonanej operacji, włącznie z użyciem tooli, ilością tokenów, czasem wykonania, kosztami — to kluczowe elementy całego procesu.
Nie chodzi tylko o wsteczną analizę potencjalnych błędów.
O wiele ważniejsza jest rozbudowana baza wiedzy pod optymalizowanie procesu.
Coś, co niemal zanikło w programistycznym świecie (taniej kupić mocniejszy serwer niż optymalizować kod), w przypadku modeli nabiera zupełnie nowego znaczenia. Staje się wręcz kluczowym punktem.
Jasne, na start wystarczą zwykłe logi tekstowe. Serio. Zapisujesz prompt, odpowiedź, ile tokenów poszło, ile to kosztowało — i już masz z czym pracować. Nie trzeba od razu wskakiwać na głęboką wodę.
Natomiast jak projekt rośnie, zaczynasz testować kilka modeli równolegle, masz setki zapytań dziennie i chcesz porównywać wersje promptów — wtedy zwykły plik tekstowy przestaje wystarczać. I tu wchodzą dedykowane narzędzia. Langfuse jest open source — stawiasz u siebie i masz pełne trace’y, wersjonowanie promptów, tracking kosztów. Helicone jest jeszcze prostsze — podmieniasz base URL w API callu i gotowe. Tokeny, koszty, latencja — wszystko leci na dashboard.
Oba mają darmowe plany na start. Dopiero jak zaczniesz widzieć co się dzieje pod spodem, zyskujesz realną kontrolę nad zmianami i analizą. Bez tego jesteś po prostu ślepy.
Jeden prompt, duża zmiana
Podam Ci bardzo prosty przykład.
Buduję agenta, który ma używać Agent Search do wyszukiwania danych w plikach markdown.
Mam jeden prompt systemowy, ale testuję równolegle kilka modeli:
- MiniMax M2.7
- Gemini 3 Flash Preview
- GLM 5 Turbo
- Claude Haiku 4.5
- GPT 5.4 Mini
Wystarczył jeden prompt: przeanalizuj poprzednie zapytania i zaproponuj zmiany w prompcie systemowym.
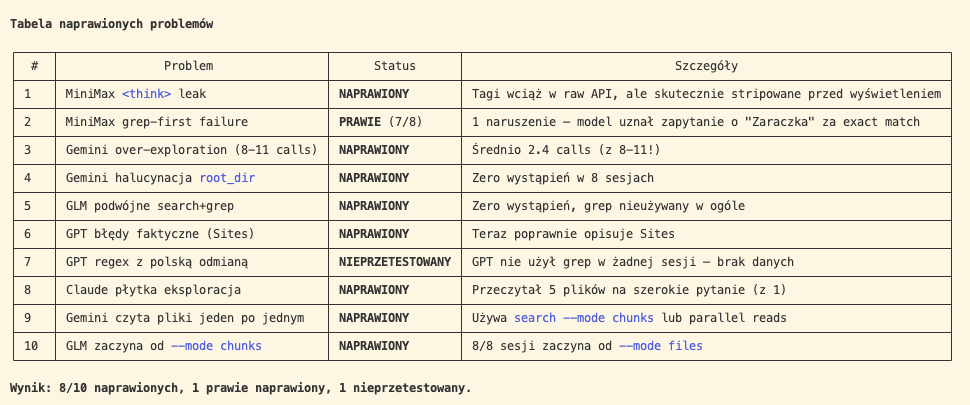
Efekt? Znacznie mniej tool calls — a co za tym idzie, mniej tokenów i mniej spalonych $. Jakość odpowiedzi nie spadła. Momentami nawet wzrosła.
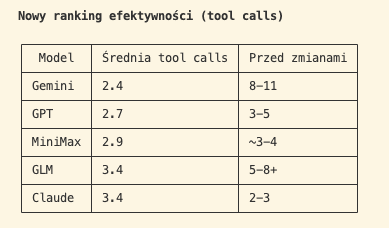
Gemini i GLM — największy skok poprawy. Claude minimalnie wzrósł (bo teraz czyta więcej plików na szerokie pytania — to pożądane).
Nie tylko ja
I tu ciekawostka. To podejście — pozwól modelowi optymalizować proces — nie jest moim wymysłem. Nabiera rozpędu.
DSPy ze Stanford NLP robi dokładnie to, o czym piszę wyżej. Nie piszesz promptu ręcznie. Definiujesz co ma wejść i co ma wyjść, a framework sam generuje i optymalizuje prompt pod spodem. 160 tysięcy pobrań miesięcznie, więc to nie jest żaden eksperyment — ludzie używają tego w produkcji.
Andrej Karpathy (tak, ten od Tesla AI i OpenAI) poszedł jeszcze dalej ze swoim Autoresearch. Dajesz agentowi AI setup treningowy modelu, idziesz spać, a rano masz wyniki ze stu automatycznych eksperymentów. Agent sam modyfikuje kod, odpala trening, ocenia wyniki i decyduje co zostawić, a co wyrzucić.
Widzisz schemat?
Ja optymalizuję prompty systemowe. DSPy optymalizuje prompty automatycznie. Karpathy optymalizuje cały kod treningowy. Wspólny mianownik: człowiek definiuje cel, model szuka drogi.